Python - Introdução ao Pandas
Básicos do plugin Pandas para o Python:
Trabalhamos com Séries e Dataframes. Series é como se fossem as colunas no Excel e os Dataframes como se fossem as Tabelas.
Aqui, cada elemento das Series pode ter uma label. Por exemplo:
my_list = ['melão','laranja','maçã']
criamos uma lista para os nossos elementos
etiquetas = ['fruta1','fruta2','fruta3']
criamos uma lista que servirá para chamar esses elementos
Assim, para criarmos uma Serie dentro do Pandas:
x = pd.Series(data = my_list, index = etiquetas)
no data colocamos os nossos elementos e no index a nossa lista das etiquetas.
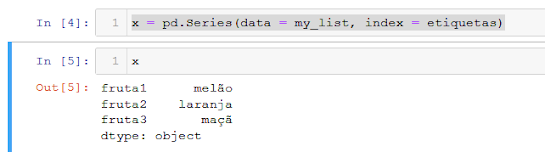
Quando chamamos a nossa variável x, já temos portanto a nossa Serie criada.
Para criarmos um DataFrame (tipo tabela no Excel), usamos a seguinte sintaxe:
df = pd.DataFrame({'Nome':['Sérgio','Inês','Beatriz','Henrique'],'Idade':[42,32,7,6],'Cidade':['Porto','Lisboa','Almada','Lisboa']})
Criamos uma variável (df), e dizemos que é igual a pd.DataFrame(nome da função), abrimos parenteses, depois chavetas e o primeiro elemento que colocamos é como se fosse o título da coluna. O segundo é o valor que estará logo por baixo desse título. Podemos colocar vários elementos uns a seguir aos outros separados por vírgulas. É como se fosse um dicionário transformado em tabela:



Para acedermos a elementos dentro das séries, recordemos a série que criámos:





E aqui temos a tabela que queríamos, dentro do Python, pronta para se poder fazer tudo o que quisermos com ela. Podemos por exemplo criar uma tabela com os campos que nos interessam usando o comando drop e apagando colunas:




Comentários
Enviar um comentário